特許翻訳の特性と AI 時代に求められる翻訳者の役割
クライアントの声 第 2 弾
一般財団法人 日本特許情報機構(Japio)
本特集では、翻訳分野におけるクライアント企業の取り組みや翻訳の特質、業界の現況と今後の展望を紹介しています。第2弾となる今回は、総合特許情報サービスのパイオニアである一般財団法人 日本特許情報機構(Japio)の専務理事・小林 明氏にお話を伺いました。
Interviewer:JTFジャーナル編集長(JTF専務理事)、株式会社インターブックス代表取締役 松元 洋一
●日本特許情報機構の沿革
松元:本日はよろしくお願いします。まずは沿革についてお伺いします。ホームページでも拝見しましたが、1970年代に日本の特許制度の必要性から設立されたと理解しています。
小林:日本特許情報機構(Japio)になったのは1985年(昭和60年)で、その前の1971年に設立された財団法人日本特許情報センター(Japatic)が前身になります。
1970 年に特許の公開制度ができました。それ以前は、出願された発明が特許庁で審査され、特許になる
ものだけが公開されていました。特許にならないものは情報が表に出てこないので、そういう情報も活用し
て発明活動をもっと積極的にしてもらおうという意図もあり、特許を出願して 1 年半経ったら公開するとい
う制度が 1970 年にできました。
そうやって特許の情報をどんどん公開し、その情報を有効に使って、よりよい発明を生んでもらえるように、「コンピューターを使って皆さんに情報を見ていただける環境を作りましょう」ということが、法改正時に国会の附帯決議という形で付されました。それを行うための団体として日本特許情報センターができたのが1971年です。

『Japio YEAR BOOK 2025』
その後、1985年に日本特許情報機構になったわけですが、特許関係の団体は日本特許情報センターだけではなく、社団法人発明協会があり、当時、そちらでも特許情報を扱っていた部分があるので、その情報関連業務とこのセンターを集約し、特許情報に関する事業を扱う団体として財団法人日本特許情報機構(Japio)が設立されました。
1978年には、特許情報を検索できたり読めたりするシステムが構築され、皆様に使っていただくという状況はできていました。もう今はなくなってしまいましたが「パトリス」というシステムで、特許の業界の方にはよく知っていただいていました。
松元:名前をよく聞いたことがあります。
小林:当時は、紙の公報だったのですが、それをスキャンしてその画像ファイルにテキスト情報として分類や要約といったものを付けて検索対象として皆さんにオンラインで使っていただいていました。
当時の「オンライン」は現在のようなインターネット環境ではなく、電話回線にカプラーを接続して利用するものでした。FAXのような音声信号を送信し、それをコンピューターが読み取る仕組みでした。画面も、マウスでクリックして表示される形式ではなくて、全部コマンドで操作して検索結果の文章やキーワードが出てくるような状態のものでした。
その後、Japio自体は、パトリスのサービスを営業譲渡・民営化しました。特許庁が1990年12月から、電子出願を受け付けるようになり、出願はテキスト情報で扱われるようになりました。そして1993年から、CD-ROM公報といって、先ほど紹介した公開公報や特許になった公報について、CD-ROMデータで提供するようになったのです。そういう情報がたくさんたまってくると、民間でもオンラインで検索するシステムを作れるようになって、今ではいろいろな会社がシステム構築をして特許情報を皆様に提供しています。
●世界特許情報全文検索サービスJapio-GPG/FX
小林:Japioはその後、世界中の特許の情報を日本語で検索できたり読めたりする環境をオンラインで皆様に提供しましょう、ということで2014年に作ったのが、「Japio-GPG/FX(Japio 世界特許情報全文検索サービス)」です。「Global Patent Gateway」の頭文字を取ってGPGなんですけれども、ネット環境の中で世界中の特許の情報を、外国語例えば英語で出ている情報であっても、日本語化したデータでも蓄積して、オンラインで検索できる状態にしました。
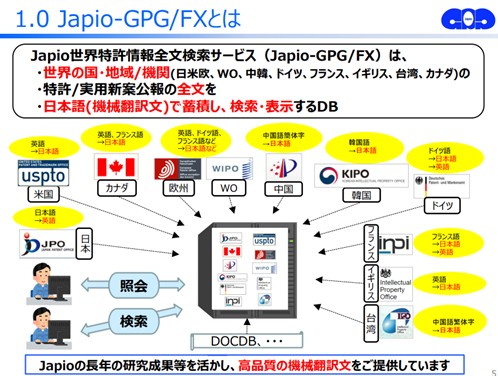
https://japio.or.jp/service/files/Japio-GPGFX-presentation_202510.pdf
GPG/FXは英語圏に限らず、海外の特許庁が発行する情報を幅広く持っています。
松元:それを機械翻訳で日本語にしたものが公開されているということですか。
小林:はい。スライド(上図)にあるように各国原語を各国原語とともに日本語化した情報も持っていて、日本語で世界中の公報の情報を一括で検索できる状態になっています。
松元:それは便利ですね。
小林:日本語化していくのに機械翻訳を使っています。下記がGPGの画面です。

松元:これはAI翻訳ではなくて機械翻訳なんですね。
小林:はい、蓄積している日本語データはAIによる翻訳ではないです。
松元:MT(機械翻訳)自体はどちらのエンジンですか。
小林:統計的機械翻訳(SMT)エンジンを使っています。翻訳文は、前後の処理などをして、特許情報のフォーマットに適したより正確なものをJapioのシステムとして利用していただけるようにしています。
2020年には、AI翻訳のサービスもオンラインで提供するようになり、このAI翻訳のシステムは、GPGのシステムとも連携していて、GPGで見ている文献をより読みやすい情報で見たいという場合、文献表示中でも画面上のボタンを押すことで、AI翻訳による日本語で読めるようになっています。
●特許情報に関する機械翻訳研究会
小林:また、今から20年以上前の2000年代初めの頃から、アジア太平洋機械翻訳協会(AAMT)とJapioは協力関係を持っていて、特許情報に関する機械翻訳の研究会を行っています。
松元:20年以上前からですか。そんなに前からやっておられたんですね。
小林:はい。当時はまだ市販の機械翻訳システムといえばルールベースでした。ルールベースの機械翻訳から、統計翻訳や文節のフレーズベースのような感じでやっていきましょうということで、長尾真先生や辻井潤一先生に委員長になっていただいて、いろいろ進めてきました。それが花開いて、こうやってシステムにしまして、さらにAI翻訳という形でやって来れました。

Japio自体は、特許情報機構というぐらいですから、特許情報の専門家として普通の翻訳は一切やっていません。逆に言うと、特許に特化してよりよい翻訳結果を出せるような研究をしながら、それを成果として皆さんにご利用いただくようにしています。
松元:実際に企業の特許明細書を翻訳して提出するとか、そういうことはされないわけですね。
小林:翻訳会社ではないので、それはしていません。
松元:国のためというか、特許全体のためにサービスを提供しているということですね。
小林:そうです。多くの企業の方や発明者の方に見ていただく、または、発明者との関係で第三者として情報を調べておかないといけないという人に見ていただくシステムで、特許庁にも使っていただいています。
●特許出願と関連翻訳の特性
小林:特許というのは、それぞれの国に出願してその国で権利を取る。その国でのみ有効な権利なんです。日本で権利を取りましたといっても、アメリカで誰も同じ技術の権利を持っていなければ真似されてしまいます。
ですから、「世界中に製品を出すなら、世界中の権利、製品を出す国の権利は取っておきましょう」ということで、日本の企業であれば、日本に出願してから1年後までは優先権という猶予があるので、その間に海外にも出願するという形で、海外の権利を取っていきます。逆にアメリカの出願人であれば、アメリカで取ってヨーロッパでも取り、日本でもその製品を出すのであれば日本でも取る、ということをやっています。
これは、同じ発明を日本語で表現する、英語で表現する、場合によって中国語で表現する。同じ発明が各国語の言語になって、出願され公開されることになります。例えば、日本語と英語でまるで同じ情報があるのでコーパスが作りやすいというのもあり、特許情報というのは、対の言語の同じ内容のものがあるのでとても便利だということで、研究材料としても有効で重宝されてきました。
一般の文章では日本語に対して翻訳された英語の文章を集めないと機械翻訳の学習データとして使えませんが、特許の場合は機械翻訳の研究者が翻訳文を作成しなくても、各国で出願され公開された同じ発明の情報を集めることでコーパスとして大量のデータができるので、機械翻訳の研究材料、研究データとして有効だということもあって、特許情報の機械翻訳の研究が始まっています。
松元:MTも分野によってはまだレベルが難しいものもあるかもしれませんが、特許においてはいち早くレベルが高い状態まで来たと思うのですが。
小林:今の説明だとそう思われますよね。権利として同じものを取るから、同じ発明が文章としてそのまま外国語になっていると。ただ、特許の法制度というのは国によって違うところがあり、「これが発明です。私が権利を取りたいのはこういうものです」という書き方が国によって違ったりするので、出願人は単純な翻訳ではなく、その国の制度に合わせた文章を作っていくことになります。「特許請求の範囲」というのは権利範囲になるもので、その説明が「明細書」といって、詳細な説明文が付くのですが、同じ発明でも出願先国ごとに違う表現や異なる文章になり原語と他言語で完全な1対1ではないというところがあるんです。
元は大量にデータがあるから学習や研究するのにとてもよい形だったけれど、よく見ていくと、やはり違う。そこを間違えて、同じ発明だからこことここに書いてあるのはみんな一緒だろうと使ってしまうと、間違いが起こるんですね。
ですから、そういうところをきちんと見極めてやっていかないといけない。場合によっては人の目を介して、同じことを言っていると確認しなければなりません。例えば技術用語では、日本語には存在するが外国語には対応する語がないケースもあり、その時点で齟齬が生じてしまいます。そういうことも気にしながら学習データを作っていかなければいけないのが、今の特許翻訳の難しさだと思います。
また、機械翻訳の精度はBLEUやRIBESなどいろいろな評価指標がありますが、これらの評価値の大小が翻訳の質と単純に線型的な関係があるのか疑問に思うところもあります。