LocWorld33 - Shenzhen 2017
LocWorld33 - Shenzhen 2017
LocWorld33 - Shenzhen 2017
日時●2017年2月28日(火)~3月2日(木)
開催場所●Marco Polo Shenzhen(中国、深圳市)
テーマ● Continuous Delivery
報告者●目次 由美子(XTM International)
ローカリゼーション業界の発展のため、友好に満ちた交流の場の形成を目的として開催されているLocWorld(以下、LW)は2003年に米国シアトルで初めて開催され、2013年以降は北米、欧州、アジアの各地で毎年1回ずつ開催されている。アジアでは東京や上海で開催されたことのあるこの翻訳イベントは、今年は中国の深圳で開催された。
深圳市は「中国のシリコンバレー」と呼ばれることもあるそうで、香港にもほど近く、街並みからも国際性が伺えた。金融センターとしての機能を有するのみでなく、政府主導による振興事業発展へ向けてのインフラが整備されているとのことだ。

深圳市の街並み
筆者自身はLWは2回めの参加となり、1年ぶりの再会を喜び合う出展者や登壇者のほか、インターネット上でのみの知人と面識を得る機会にも恵まれた。
2月28日にはゲームのローカリゼーションをトピックとしたラウンドテーブルなどがプレカンファレンスとして開催された。3月1日は3トラック、2日は4トラックで合計29のカンファレンスがメインプログラムとして開催された。この2日間は日本でも有名なマルチランゲージベンダを含む21社による展示会もあり、最終日には「アンカンファレンス」が催され、盛況の内にイベントは幕を閉じた。
基調講演の1つは中国のアジアに対する影響、もう1つは人工知能とビッグデータに関するトピックであった。カンファレンスにおいては翻訳支援ツールやAIに関するセッションはもちろん、アジアに本拠地を置く企業によるローカリゼーションについてのパネルディスカッションや、ミャンマーでのスマートフォンのローカリゼーションに関するトピックなど、地域的な特色が前面に表れるセッションも目立った。中国では政府によるインターネット規制によりGoogleやFacebookなど特定サイトの閲覧は不可能であるが、Google社によるカンファレンスがあったことも特筆しておきたい。

人が溢れる展示会場
中国に支社やパートナー企業を有する日本の翻訳会社も積極的に参加するであろうという筆者自身の個人的な予測は覆され、日本から、および日系企業については参加者としても目立たなかった。中国の翻訳団体のブースや、中国で独自に開発・展開をしている翻訳ツールベンダも見かけ、カンファレンスが開催される合間には実に多くの参加者が展示会場に足を運んでいた。
LWは交流の場でもあり、ランチやディナーも参加費に含まれている。Women in Localization(ローカリゼーションに携わる女性のための非営利団体、日本支部もある)専用のテーブルが設けられたり、TAUS(Translation Automation Users Society、世界の翻訳業界で機械翻訳などイノベーションを推進するシンクタンク)に特化したトラックが設けられるなど、翻訳に関する世界的な団体とも調和し、ローカリゼーション業界においてさらなる効果が発揮されているように実感できた。

Women in Localization専用のランチテーブル
以下では、カンファレンスの1つについて報告する。
日時●2017年3月1日(水)16:30~17:15
開催場所●Marco Polo Shenzhen内Boston
テーマ●Calculating the Percentage Reduction in Translator Effort When Using Machine Translation
講演者●Andrzej Zydroń(XTM International)
ホスト●Anne-Maj van der Meer

世界をリードするクラウド型の企業規模の翻訳管理システム「XTM」を開発・販売しているXTM InternationalにてCTOを務めるAndrzej Zydrońによる講演は、Dublin City University(アイルランド)のQun Liu教授との共同研究に基づき、統計ベース機械翻訳(SMT:Statistical Machine Translation)がもたらす実質的な工数削減がトピックとされていた。翻訳作業にSMTを活用することにより、どれくらいの時間とお金を節約できるかは明示されていないというのだ。
講演の最初のスライドには「Language is difficult」と書かれており、外国語を習得することの難しさが指摘された。一般的には7年間のフルタイムが必要と考えられているとのこと。また、言語は進化することや、意味のあいまいさについてなど言語特有の「柔軟性」についても言及があった。
ローカリゼーションのコストが考慮される際、純粋に「翻訳」という作業のみが該当するのではない。プロジェクト マネージャによる管理タスクや、チェック、校正などの作業も経費を構成する要素である。たとえばワークフローの自動化をもたらす翻訳管理システムを導入することによって、ローカリゼーション プロセスにおける管理工数を大幅に削減することも可能である。
Zydroń氏はコーパス蓄積の必要性、構文、分野の類似性などSMTの限界を羅列し、機械翻訳の究極の限界として「翻訳するためには理解が必要である」と述べた。しかしながら、機械翻訳を使用することで生産性が多大に向上する可能性も指摘した。とはいえ、機械翻訳ベンダーは導入効果に関する明確な数値を示してはくれないという現実もある。
そして、言語の親密性(Language Closeness:LC)が解説された。SMTの訳出には文法や語順など、言語間の相違が関与する。たとえば英語をソース言語とすると、ターゲット言語であるフランス語のLCは0.800、フィンランド語は0.500、日本語は0.250と考えられている。
SMTの活用に際しては、トレーニング データのサイズも重要である旨が指摘され、次の式が示された。
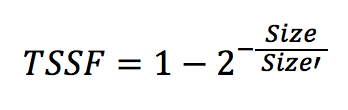
トレーニング データのサイズが小さい場合でもドメインのトピックが同じであれば、大きいサイズの一般的なトピックのトレーニング データよりもSMTでは良質の結果が出力されると考えられていることも述べられた。
そして、SMTを活用した翻訳者による尽力の縮小率(Percentage Reduction in Translator Effort:PRTE)、つまりSMTを利用することによる翻訳作業における尽力の削減を計るための公式が次のとおり示された。

たとえば英語から日本語への翻訳において、LC値は0.250、理想的なトレーニング データ値1があり、ドメインの類似値1があったとしても、翻訳に対する尽力は25%削減されるのみと考えられる。ところが、トレーニング データとドメインの類似値が同じで、ターゲット言語がフランス語であった場合、LC値が0.800であるため、翻訳に対する尽力は80%削減されると考えられるというのだ。
この、PRTE値は翻訳における尽力の削減を強固に迅速に示すものではないが、SMTの導入効果としておおよそ期待できる予測値が示されるとのこと。LC値についてもおおよその予想に基づくものであり、特定のSMTシステムでチューニングが実施された場合には、より良い値が示される可能性もあり、個別のSMTエンジンについても考慮してはいない。しかしながら、PRTE公式はSMT導入効果として期待できる、参考となる数値が示されるものであると考えている。