
[イベント報告]これからの特許翻訳~特許翻訳の特徴/NMTの評価とPEのノウハウ
2020年度第3回JTF翻訳セミナー報告
- テーマ:これからの特許翻訳~特許翻訳の特徴/NMTの評価とPEのノウハウ
- 日時:2020年12月10日(木)14:00~16:00
- 開催:Zoomウェビナー
- 報告者:伊藤 祥(翻訳者/ライター)
登壇者

宮本 伸也(ミヤモト シンヤ)
日本ビジネス翻訳株式会社 代表取締役社長、JTF監事
東京理科大学・理学部、慶応義塾大学・法学部卒。日本ビクター株式会社(現・JVCケンウッド)を経て1989年NGBコーポレーションに入社。国内外の特許調査・特許技術分析業務に従事した後、1998年より同社特許部において、外国出願の権利化・訴訟サポート業務に従事し、特許部部長も歴任。2012年、日本ビジネス翻訳株式会社へ転籍し代表取締役社長に就任。2019年日本知的財産翻訳協会(NIPTA)理事、2020年JTF監事に就任。社長業務に携わる傍ら、AIの業務応用の研究、MT+PEの研究にも余念がない。
Googleの機械翻訳エンジンがNMTに刷新され早4年が経ち、機械翻訳を取り巻く環境は、一気呵成にNMT一色となった。翻訳会社も、人手翻訳に加えNMTを利用したポストエディット翻訳(PE)、即ち「MT+PE」とよばれる選択肢を視野に入れざるを得ない状況となっている。
本講演では、前半部で、特許翻訳の特徴や注意すべき点等を、現役翻訳者である辛島氏のインタビューで紹介、後半部では宮本氏が特許明細書をNMTエンジンにかけた評価、実務のPEとして、MT+PEの課題を軽減する「CAT(Computer Assisted Translation)ツールを駆使したPE」とそれを行う上でのノウハウ、また、CATツールを使用した翻訳レビューのデモが行われた。
PEに従事する実務者の負担の軽減につながる一助にと、第一線の翻訳者の生の声と、PEの最新のノウハウが惜しみなく紹介された。
第1部:特許翻訳とその心得(現役特許翻訳者 辛島氏インタビュー)
1. 特許翻訳とは?
Q. 特許翻訳者の仕事とは?
A. 外国での特許を出願するには、その国ごとに出願する必要があるため、主に技術的な内容の出願書類を各国の言語に翻訳する必要性がある。日本の特許庁への出願件数は年間何十万件に上るので、かなりの翻訳の需要/仕事量がコンスタントにあるといえる。
特許翻訳の原稿は、極論すると家庭用の工業製品の取扱説明書を詳しくしたようなもので、製品やその製品を作る過程が取扱説明書のように記載された書類なので、特に専門知識がなくても始められる仕事だと思う。
Q. 特許翻訳に専門知識は必須なのか?
A. 専門知識は非常に有用だとは思う。原稿の書かれ方によっては、技術的な方面から読み解かないと理解できないこともある。それでも、仕事を始めてからこつこつ勉強しても間に合うし、例えば電気や機械の分野は間口が広く、文系出身者でもばりばり活躍している人がたくさんいるそうだ。
一方で、自分はこれこれの分野が得意であるという売りがあったほうが仕事をとりやすい気もする。ただし、語学力がずば抜けて高いのであれば、それだけでも仕事はあるかも知れない。
まとめると、専門知識は必須ではないが、あれば仕事がしやすいかもといったところか。
2. 特許翻訳をする上での心得
Q. 電気・機械は文系でも従事者がいるとのことだが、目指す方にむけて勉強法をご紹介いただきたい。
A. 原稿が特許文書として完全である場合には、未知のことはウェブや過去の関連資料で調べれば読み解き、翻訳できると思う。文系出身者でも、興味を技術系にもっていったり、理系が苦手だった人でも、昨今は昔よりわかりやすい教科書なり資料が出ているので、以前より学習しやすい。
最初に注意されたことは、特許用語には法律用語のように定訳があるので、それを外さないということだ。外すと信用を落としてしまう。他の翻訳分野もそうであろうが、特許は特にその傾向が強い。例えば、aspectは態様、embodimentは実施形態、the artは当分野、those skilled in the artは当業者と訳すなどである。技術用語にも定訳があり、バイオ系ではtemplateは(DNAの)鋳型、expressionは(タンパク質の)発現だが、プログラミング系のexpression templateは式テンプレートになる。このような用語は参入のハードルではないが、絶対気をつけないといけない。
さらなる注意として、特許文書というのは法律上の文書なので、誤訳・意訳はしないこと。誤記や訳抜けは言い逃れできない。原稿中に文法的な誤りなどがあれば、顧客にわかりやすく伝える必要がある。
迷ったら調査すること。例えば、多くの出願原稿には、同一出願人または同業出願人による過去の類似の出願がある。その場合は訳文を自分で案出するより、公開されている過去の出願からお手本を探して翻訳/学習するほうが確実。大先輩からは、分からないことは自分の脳内で解決しないで調べなさいと指導された。
調べるためのウェブサイトは外国の特許はWIPO、日本の特許はINPIT。特許翻訳全般の教科書としては「外国出願のための特許翻訳英文作成教本」。「J-STAGEのサイト」に翻訳者の心得のPDFが公開されている。「NCBI」で英語のバイオ系論文、「J-STAGE電子ジャーナル」では和文科学系論文の検索/閲覧が可能。
リサーチはグーグル検索でいけるなどという極論もあるぐらいなので、これを揃えないとダメだということはない。
Q. 現在の仕事の状況について伺いたい。顧客からの要求とはどのようなものか?
A. 翻訳文に問題があり特許が取得できないと、莫大な損失になり得るから気をつけなければならない。最低限、誤記・訳抜け・原文にないことを追記しないことは必須だ。
Q. 月間にどのぐらいの量の仕事を受けているか?
A. 多くて英文で10万ワードぐらい。特許翻訳では、いったん受注できれば継続してもらえる安心感がある。
Q. 2020年のコロナの影響はどうだったか?
A. 20年の初夏は減って、秋からリバウンドした。国外の経済が回ってるかが如実に現れた。
Q. 苦労している点はなにか?
A. 案件の分野は専門分野なので、技術的な苦労は少ないが、締め切りがタイトであるとつらい。細かいことだが、締め切りがタイトでかつファイル形式がWordでないときはまずい。なるべくWordで原稿が欲しい。
第2部:NMTとCATツールによるPEの進め方(宮本 伸也氏のレクチャー)
ここからはPEの作業者の参考になる情報を提供したい。武士道的な大義の話をするより、どうやってツールであるMTを使いこなすか、剣術的な話をしたい。
1. いざMT+PEの時代へ!
かつての統計型機械翻訳(SMT)は“Better than nothing?”だったが、ニューラル機械翻訳(NMT)になり“Better than typing?”といわれるようになった。人手翻訳の人の作業の6割はタイピングという研究結果もあるので、翻訳者からは機械翻訳はBetter than typingだけでも使う価値があるという認識に変わりつつある。
さらに、最近のNMTともなると、少ないデータ量で学習し自然な訳文を出力するカスタマイズ機能も利用できるようになってきた。そしてCATツールとの融合が進歩し、MTとAPI接続できる便利な機能が拡充されてきた。これによりポストエディットもより効率的に進められるようになってきた。
2. 最新NMTの実力
ここで、進化し続けるNMTの機能を紹介する。まず、アダプテーションが入ることによって分野別のNMTが可能になった。そして、カスタマイズによって顧客別のNMTができたり、自分流のスタイルの翻訳が自動で仕上がったりするような夢のある世界が広がろうとしている。
特許明細書に関連した特徴量に基づくモデリングという、NMTのベースとなる深層学習は、正しい答えを導き出すというより、データセットという入力から出力にいたる特徴パターンを解析し関数を導き出す作業だ。MTの学習とは、非線形関数モデルを最小の誤差で構築することなので相対的で、PEは必要不可欠となる。最小の誤差を誤差のない範囲まで持って行く作業は人間がやる。
特許分野は公開制度があるので学習データとしては申し分ない量がある。このスケールメリットを活かし最新のアルゴリズムを取り込んだ翻訳エンジンが開発され、最近のエンジンは仕事で使えるレベルになってきた。
3. NMTのエラーパターン
今回の実験で取り上げたのはNMT(第2世代)エンジンで、原文は日本知的財産翻訳協会使用許可済の知的財産翻訳検定試験の過去問題を使用した。文字数は800ワードと少なく部分的なものであり、かつ学習データと照合もしていないのでエンジンの中には学習時に過去問を解いていた可能性もあり、翻訳エンジン性能そのものを決定づける評価ではないが、参考値として結果は以下の通りとなった。
- N型エンジン(近々第3世代へ進化予定)
- 官民で開発されたエンジン
- 請求項を正確に訳出、一方で未訳あり
- T型エンジン(カスタマイズ可能)
- 民間エンジン
- 基本性能は良いが長文の請求項には歯が立たなかった(カスタマイズなしのベースエンジンでの評価)
- D型エンジン(誰でも利用可)
- ドイツで開発されたエンジン
- こなれた英語表現だが多少用語のバラつきあり(しかし、別の実験では、用語統制がとれていたという実験結果もあるようだ)
MTの下訳をどれだけ援用したかで評価し、翻訳エンジン別にみた適訳精度をヒストグラムにした。マッチングレートがあがっている箇所は、ポストエディターの負荷軽減につながっている。
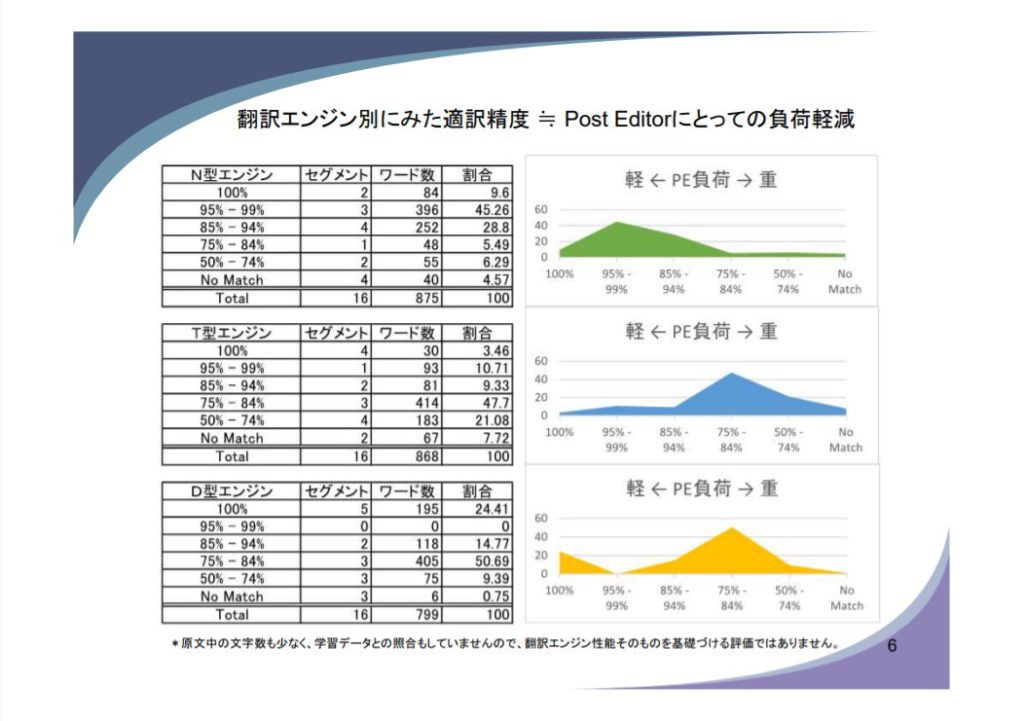
N型の例ではMTそのまま100%正解が9.6%、95-99%が45%。これが定格出力ならPEは不要だが、感覚的にはT型のピークの80%台が一般的なMTエンジンの実感値に近い。しかし、ピークが50%ぐらいであった頃と比べると進化している。最近ではNo Matchとなる50%以下が減少している。MTには誤訳、不明瞭訳とMT翻訳特有のエラーがあるが、2020年に入って低減されてきた。
4. 特許明細書が読みにくい最大の原因:前置修飾と後置修飾
特許明細書が読みにくい最大の原因は非常に長い前置修飾にあり、主に形容詞節と副詞節が難しい。
【例】
計測済みデータと、コントローラによって実際に調整されているガスの流速、取り付けられているチューブの長さL、ヘッド温度Tとに基づいて、実際に熱処理を行っている際の、若しくは、実際に熱処理を行う前の基準ヒートガスヘッド圧力損失を求め、(以下略)
例文では、形容詞節として「実際に熱処理を行っている際の、若しくは、実際に熱処理を行う前の」が「基準ヒートガスヘッド圧力損失」にかかり、副詞節として「計測済みデータと、コントローラによって実際に調整されているガスの流速、取り付けられているチューブの長さL、ヘッド温度Tとに基づいて」が「求め」にかかっている。
これを翻訳する際の、英日の文法構造が異なることを利用した要となる手法を、私は「前置修飾・後方送致翻訳」と呼んでいる。日本語の前置修飾部を英語では後置修飾にする。ポストエディットはこういう作業を行い、最終的な読み手、海外の特許出願手続きであれば審査官にわかりやすくする。
5. 一体不可分なPEとCATツール
MTによる下訳をポストエディット(PE)して作成した文章を、論理的な文章表現にするために、ツーリストがチェックする。適切な用語選択や誤訳・脱訳のチェックはCATツールを使って効率的に行う。それら結果が翻訳メモリ(TM)上に蓄積されていき、コーパスはMTの学習データとして活用される。このように、PEとCATツールは一体不可分となりつつある。主なCATツールには、SDL Trados、memoQ、Memsource、Xbench 10などがある。
CATツールの基本機能には、①翻訳プロジェクトの作成(原稿のアップロード、翻訳者のアサイン、納期管理、TM/TBの選択)、②翻訳メモリ(TM)の作成管理、③用語ベース(TB)の作成管理がある。専用エディターを使ったレビューでは、①TMによる翻訳資産形成、②用語リストの一元管理/用語統一、③QA(Quality Assurance)によるチェック、④バイリンガルファイルの出力が可能となる。
6. 正規表現を利用したチェックとは?
CATツール機能を利用してPEを行う目的は、ポストエディターの認知負荷を軽減することにある。PEは認知負荷が大きいストレスフルな作業であるといわれ、それを軽減できないかと、CATツールで正規表現機能が使えるようになったので、その活用を考えた。
正規表現とはファイル名をあらわす特殊記号「メタキャラクタ」で構成される文字列パターンであり、これを利用して特別にルールづけられたテキスト検索を行う。明細書チェックでよく使う正規表現を一通り以下にあげる。
| . | 任意の一文字 |
| * | 直前の式、文字の繰り返しと一致 |
| [abc] | 文字セットの指定 (←abcのいずれかに一致) |
| ^ | 除外する文字セット/入力文字列の先頭と一致 |
| {n,m} | nからm回の一致 |
| x|y | OR 論理記号 (←x又はyと一致) |
使用例
| 原文側 | よりも.[^、]{3,20}通電し.|前に|極性|期間の比率である.[^、]{3,20}と|期間である.[^、]{3,20}と|組み合わせ |
| 訳文側 | than|energize|before|polarity|period|ratio|combination |
| 原文側 | されている|された|によって|るよう|場合|状況|状態|ることで |
| 訳文側 | that | which | by | with |when |case of |case that |so that |so as to | situation| state |
上の例のように、訳文側で使われそうな前置詞や構文を入れておいてチェックする。一対一で対応させてチェックする必要はないし、対応できるわけでもないが、目的は認知負荷の軽減なので大雑把でも目的は達成できる。
7. 実践デモ
① 正規表現を利用したチェック
このデモでは、NMTエンジンはN型エンジンとT型エンジン、テキストは知的財産翻訳検定試験の過去問題、CATツールはMemsourceを使用した。フィルタボックスで原文用の正規表現を使い該当セグメントのみを表示し、誤用されやすい原文部分をマーキングさせ、また、検索ボックスを使用し、訳文用の正規表現を使い、対応箇所をハイライトさせた。MTのいやなところは、しれっと間違えることだ、例えば、デモの例ではpositiveがreverseの意味になってしまった。ところどころ落とし穴があるのをPEしていくが、対応しているところをできるだけマーキングして、いろんなところを反復確認する認知負荷を減らす。
② その他のCATツール機能を利用したチェック
次に、フィルタをクリアして、汎用的なチェックポイントを入れる。例えば、書き手の弁理士のスタイルなどの条件に合わせて作り込む。この他、用語のばらつきの消し込みについては、例えば、「自動車」でフィルタをかけると、該当部分のみ表示されるので置換のリスクが減る。これを例えばvehicleに統一したいとき、まずautomobileを検索して確認後置換、ここでanはaになるように忘れず入力する。an automobileをa vehicleで全部置換する。これ以外にも、Memsourceのツールを使えば、変更履歴をエクスポートすることもできる、解析や文章比較などについても、CATツールの機能を使用できる。
質疑応答
Q. MTは複数文で訳すと精度が上がるが、CATツールはセグメントごとに細かく区切ってしまうので、組み合わせると精度が下がる。どのような対策をとればよいか?
A. 確かに、文章は寸断されていない方がMT出力の精度もよいので、最初に文章の改行キーを@に置換してCATツールにアップロードし、バイリンガルファイルを出力してから@を改行キーに戻すと、短いセグメントとならない。このような工夫は手間だがNMTの御利益があるのでやってみるとよい。
Q. TM+MT+PEの合わせ技は実施されているか?
A. TMあってのMTなので、TMはかかせない。なぜならばMTのカスタマイズはTMで蓄積されたコーパスを使用しているからである。ちなみに、TMを活用して一括翻訳する場合、マッチ率は90%以上にした方がいい。80%くらいでも下訳として使えないこともないが、MT翻訳を修正した方が楽であろう。
Q. PEの案件は、単価が下がるのか?
A. MTだからと安売りはしない。あくまでもPEを利用して効率よく翻訳するため。余力ができたら、よりクリエイティブな部分に時間を割いてもらう。特許翻訳では、1カ所で数分考える表現もある。MT出力原稿を入手するなら、クライアントやプロバイダーから入手するのがいい。当社でいえば、これまで人手翻訳を売りにしていたので、PEでもクオリティを下げない。フルポストエディットができる人はMTより知見ある人なので業界としても安売りはよくないと思っている。