翻訳の手作業を効率化する「正規表現」
第7回:正規表現による置換のしあげ
翻訳者、JTF副会長 高橋 聡
この連載も、とうとう最終回になりました。今回は、前回の後半で紹介した置換の機能に、ちょっと高度な正規表現を組み合わせた、「これぞ正規表現の極意」ともいえる置換について説明します。最初はなかなかややこしいかもしれません。必ず(今までと同じく)自分でも試しながら読み進めてください。
さっそくですが、
コンピュータ[^ー]
この検索パターンを覚えていますか? 第5回で扱いました。「コンピューター」つまり長音ありの形にはヒットせず、「コンピュータ」つまり長音なしの形にだけヒットするという指定です。大カッコ[ ]の先頭にキャレット(^)を付けると、その後ろに続く文字列をすべて「否定」する、つまりキャレット(^)の後ろに指定した文字が「ない」パターンにヒットするのでした。
では、このパターンを使って長音なしの「コンピュータ」をすべて長音ありの「コンピューター」に置換するにはどうすればいいでしょうか。ためしに、
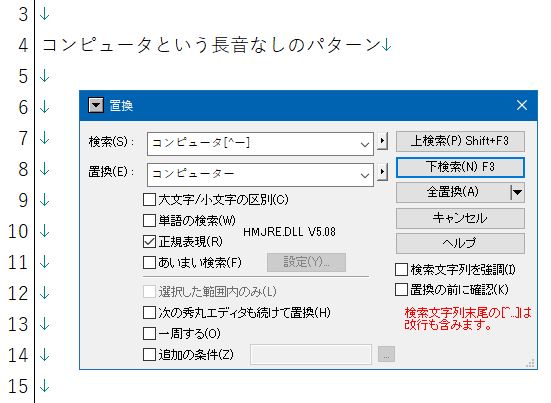
「コンピュータという長音なしのパターン」と書いたテキストファイルで、この図のように指定して置換を実行するとどうなるでしょうか。ぜひ試してください。置換後の結果はこうなるはずです。

「という」の「と」が消えてしまいました。なぜこうなるのか、1分間考えてみましょう。それで分からなかったら、Ctrl+Zを1回押して元の状態に戻したうえで、置換ではなく検索でヒットしたときの強調表示の状態をじっくり眺めてみてください。
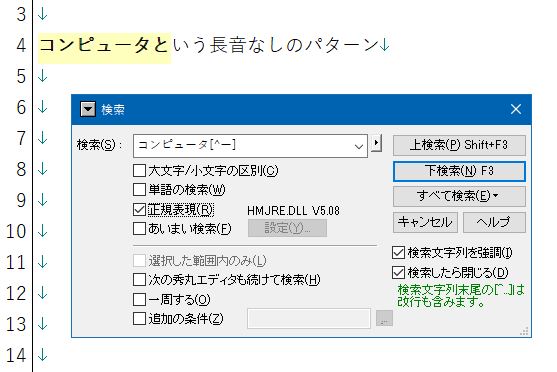
お分かりでしょうか。「コンピュータ」までではなく「コンピュータと」まで強調表示されています。これが、キャレット(^)を使った検索のトリッキーなところなのです。先ほど、
キャレット(^)の後ろに指定した文字が「ない」パターンにヒットする
と書いたばかりですが、厳密にいうとこの表現は正しくありません。"指定した文字が「ない」" のではなく、"指定した文字以外にヒットする"のです。つまり、
コンピュータ[^ー]
という指定も、「コンピュータ」の後ろに「長音がない」箇所ではなく、「コンピュータ」の後ろに「長音以外が続いている」箇所にヒットする、の意味になります。実際、上のスクリーンショットを見ると「コンピュータと」までが強調表示されています。[^ー]の部分が「と」にヒットしているわけです。
そうなると、ここまでに覚えたルールだけでこの置換を実現することはできません。新しく、半角丸カッコ ( ) による文字列のグループ化という指定ルールが必要になります。丸カッコは、
industr(y|ies)
という指定にも使いました(第5回を参照)。丸カッコ () の中で縦線(|)を使って「AまたはB」を表す指定です。同じ指定を[ ]で表すことはできません(理由は考えてください)。今回の丸カッコは、それとはちょっと違うルールです。まずは、上で失敗した置換を、以下の図のように変えて実行してみてください。丸カッコもすべて半角です。
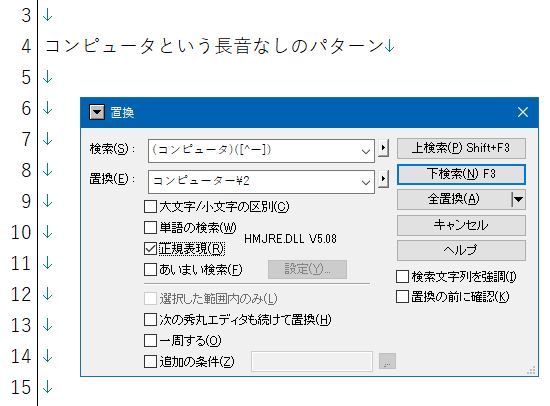
この指定でやっているのは、以下のような処理です。
- コンピュータ[^ー]という検索文字列の全体を、半角丸カッコ ( ) によって2つのグループに分けている。つまり、(コンピュータ)と([^ー])。
- このようにグループ化すると、それぞれのグループを前から順に¥1、¥2、¥3……という特殊文字で表せるようになる。この場合は
(コンピュータ)([^ー])
と指定したので、
コンピュータ => ¥1
[^ー] => ¥2
という対応になります。 - [置換]には
コンピューター¥2
と指定したので、これは「コンピューター」の後ろに¥2つまり[^ー]つまり「長音以外」が続くという意味になります。ちなみに、[置換]フィールドへの指定は
¥1ー¥2
でもいいことになります。¥1は「コンピュータ」だからです。
ややこしいですよね。もう一度このルールを言葉で説明すると、「検索文字列を半角丸カッコ () で区切ってグループ化すると、( ) で囲んだ文字列グループを、前から順に¥1、¥2、¥3……という特殊文字で表せる」です。言い換えると、「半角丸カッコで囲った部分は、置換後にそのまま残すことができる」ともいえます。
ややこしい話がさらにややこしくなりますが、実際には、上の例のように検索文字列をすべてグループ化する必要はありません。¥1、¥2、¥3……の特殊文字で表したい部分だけを ( ) で囲めば済みます。つまり
[検索]フィールド:コンピュータ([^ー])
[置換]フィールド:コンピューター¥1
と指定しても同じ置換ができるということです。( ) で区切ったグループは1つしかありませんから、[置換]で指定している特殊文字が¥2ではなく¥1になった点に注目してください。
この書き方ができたら、あとは[置換]フィールドで¥1、¥2、¥3……の特殊文字の使い方を工夫すれば、いろいろな置換ができます。ここまで進むことができると、正規表現の威力をかなり実感できると思います。
ここからは、この置換の実例とその説明をいくつか示していきましょう。これまでに覚えたルールも総動員しますので、これを読み解くことが、今までの内容の総復習にもなります。
[検索]フィールド:行な([わいうえおっ])
[置換]フィールド:行¥1
[検索]フィールドでは1つだけ丸カッコ ( ) を使っています。動詞の送りがなのうち活用語尾に当たる部分です。グループが1つだけなので、これは¥1で表せます。そこで、[置換]フィールドには「な」をとった「行」だけの直後に¥1を続けて指定しています。こうすれば、送りがな部分はそのままにして、「行な」→「行」だけを置換できるわけです。
ちなみに、「おこなう」という動詞の送りがなは、最近ではほぼ「行う」になってきていますが、出版社など一部のお客さんは今でも「行なう」を好んで使います。「おこなって」という形になるとき、前者だと「行って」になってしまい「おこなって」なのか「いって」なのか混乱するという理由です(たぶん)。そういう「な」ありのルールでしばらく仕事をしたあとで、「な」なしのルールに戻ったとき、つい「な」を入れてしまった――そんなときはこの置換が役に立ちます。
[検索]フィールド:([ァ-ヶーぁ-ん亜-熙])( )([a-zA-Z0-9])
[置換]フィールド:¥1¥3
[検索]フィールドでは、( ) を3組使っています。つまり( ) で区切ったグループが3つあるということ。1グループ目は[ァ-ヶーぁ-ん亜-熙]。日本語の中で一般的に使う文字すべてです。2グループ目は、紙面だと分かりにくいかもしれませんが「半角スペース」です(そう、グループという言葉で説明していますが、丸カッコで囲むのは1つの文字でもかまわないのです)。そして3グループ目は[a-zA-Z0-9]で、英数字すべて。つまりこれ、「全角文字と半角文字の間に半角スペースがある部分」にヒットする検索パターンなのです。
そして、[置換]フィールドには¥1¥3と指定しているので、( ) で区切った3つのグループのうち2つ目、つまり半角スペースをなくして、1グループ目=全角文字と3グループ目=半角文字だけに置換します。ということで、これは「全角文字と半角文字の間にある半角スペースを一括削除できる」置換パターンになります。ただし、これは「前が全角、後ろが半角」の場合ですから、続けて逆のパターン、
[検索]フィールド:([a-zA-Z0-9])( )([ァ-ヶーぁ-ん亜-熙])
[置換]フィールド:¥1¥3
も実行しなければいけません。
次は、上のパターンをちょっと応用します。
[検索]フィールド:([ァ-ヶー])(・ )([ァ-ヶー])
[置換]フィールド:¥1¥3
まず自分で読み解いてください。真ん中の丸カッコは「中黒または半角スペース」です。もうお分かりですね。「区切りとして中黒または半角スペースが使われているカタカナ複合語から、中黒または半角スペースを削除する」置換パターンです。
では、次はどうでしょうか。
[検索]フィールド:([0-9]+)/([0-9]+)/([0-9]{4})
[置換]フィールド:¥3年¥1月¥2日
読み解くのがだいぶ難しくなってきました。よーく見て考えてください(読み解きが勉強になります)。1分たったら解説します。
……(1分経過)……
[検索]フィールドに指定されているのは、数字とスラッシュだけで、そのうち数字だけを丸カッコ ( ) で囲っています。そして、1つ目と2つ目の数字は[0-9]+ですから、どちらも「数字1桁以上」です。3つ目は[0-9]{4}なので、これは「数字4桁」。したがってこれは、「数字1桁以上/数字1桁以上/数字4桁」というパターンにヒットする指定です。たとえば、5/26/2019または26/5/2019、12/24/2023または24/12/2023ということで、そう、アメリカ式またはイギリス式の日付形式ですね。
[置換]フィールドの指定は、¥3年¥1月¥2日。このように、¥1、¥2、¥3……の特殊文字は順番も自由に変えられるのです。もうお分かりでしょう。¥3は「数字4桁」、¥1と¥2は「数字1桁以上」です。英文での日付形式を日本式に置換できます。ただし、この置換はアメリカ式からの置換である点に注意してください。。アメリカ式は「月/日/年」、イギリス式は「日/月/年」なので、¥1と¥2の表す内容が逆になっているからです。なお、この例の[検索]フィールドは
([0-9]{1,2})/([0-9]{1,2})/([0-9]{4})
でもいいはずですよね。1つ目と2つ目は「1桁以上」ではなく「1桁または2桁」だからです。
◆ ◆ ◆
というわけで、正規表現について説明する全7回の連載が終わりました。繰り返しますが、ぜひ自分でも秀丸エディタ上で検索と置換を試しながらお読みください。翻訳者の作業で「時短」を考えるとき、正規表現が実に強力なツールになることを実感していただけるはずです。
なお、正規表現については、2023年3月に出た拙著『1秒でも長く「頭」を使いたい 翻訳者のための超時短パソコンスキル大全』(KADOKAWA)にもまとめてあります。この連載とあわせてどうぞ!
○執筆者プロフィール

高橋 聡(たかはし あきら)
CG以前の特撮と帽子と辞書をこよなく愛する実務翻訳者。フェロー・アカデミー講師。日本翻訳連盟(JTF)理事・副会長。学習塾講師と雑多翻訳の二足のわらじ生活と、ローカライズ系翻訳会社の社内翻訳者生活を経たのち、2007年にフリーランスに。現在はIT・マーケティングなどの翻訳を手がけており、翻訳フォーラム(fhonyaku.jp)などの翻訳者グループで情報発信も行う。訳書に『機械翻訳:歴史・技術・産業』(森北出版)、『現代暗号技術入門』『イーサリアム 若き天才が示す暗号資産の真実と未来』(ともに日経BP)など。著書に『翻訳者のための超時短パソコンスキル大全』(KADOKAWA)、共著に『翻訳のレッスン』(講談社)がある。